GraphRAG:AI应用新主流
信息以前所未有的速度增长,传统技术越来越难以应对。随着机器学习与人工智能的飞速发展,企业对“信息和知识密集型”任务的处理效率成为新的竞争力。
陈加兴
StrategyLogic创始人
陈加兴
StrategyLogic创始人

大语言模型虽然能够处理大量的信息,但由于其概率性本质和对特定领域知识的不完整性,经常会生成不准确的答案。为了解决这一问题,GraphRAG技术诞生,这是一种结合知识图谱和检索增强生成的创新方法,旨在通过图结构的检索机制,提升大语言模型信息检索的准确性和效率。
GraphRAG的核心优势在于将知识图谱的结构化检索能力与大语言模型的自然语言处理能力相结合。这种结合不仅提高了信息检索的效率和准确性,也为AI应用场景拓展了更广阔的空间,成为备受巨头和开源社区关注的重点应用领域。
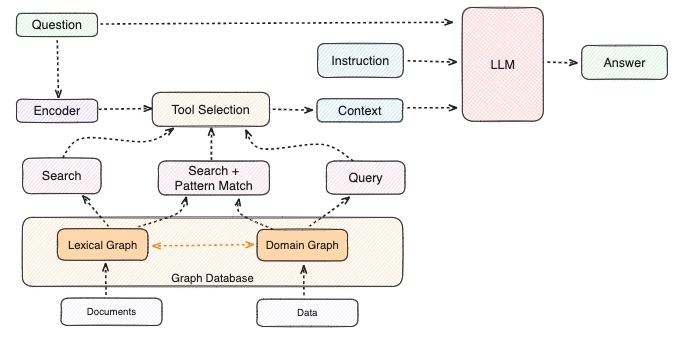
目前,除提供Graph编配支持的LlamaIndex、LangChain、LangGraph外,Microsoft、Neo4j及阿里巴巴也先后推出开源GraphRAG,使得Graph + LLM技术生态接近完善。
本文对GraphRAG的原理、优势、应用及前景进行介绍。
关键技术与优势
知识图谱是一种用于表示实体及其关系的图结构模型,能够灵活地存储和管理结构化与非结构化数据。与传统的数据库相比,知识图谱不需要固定的模式(Schema),具有更高的灵活性,能够更好地适应现实世界中复杂多变的数据关系。
在GraphRAG中,知识图谱作为语言模型的“灵活记忆伴侣”,为语言模型提供丰富的背景知识和上下文信息,从而增强其在总结、翻译、提取等语言任务中的表现。
知识图谱的构建与类型
知识图谱的构建包括数据的收集、整理、建模和存储。数据来源可以是结构化的业务领域数据、文档表示,也包括通过图算法计算得到的信号。
在GraphRAG中,常见的知识图谱1包括领域图(Domain Graph)、词汇图(Lexical Graph)和父子词汇图(Parent-Child Lexical Graph)。
1.领域图(Domain Graph)
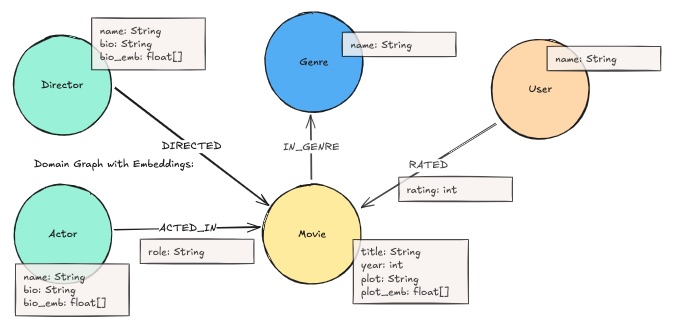
领域图是针对特定业务领域构建的知识图谱,它包含了该领域中的实体及其关系。例如,一个电影领域的领域图可能包含电影、演员、导演、制片公司等实体,以及它们之间的“主演”、“导演”、“出品”等关系。领域图通常基于结构化数据构建,能够为特定领域的应用提供精准的知识检索和分析支持。
2.词汇图(Lexical Graph)
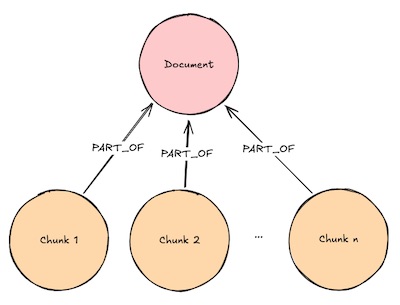
词汇图主要用于处理文本数据,它将大型文档分割成较小的文本块(Chunks),并对每个文本块进行嵌入(Embedding)处理,以捕捉其语义信息。文档节点(Document Nodes)和文本块节点(Chunk Nodes)是词汇图中的主要节点类型,它们通过“属于”(PART_OF)关系连接。词汇图在基本检索器(Basic Retrievers)中发挥重要作用,能够快速检索与用户查询相关的文本块。
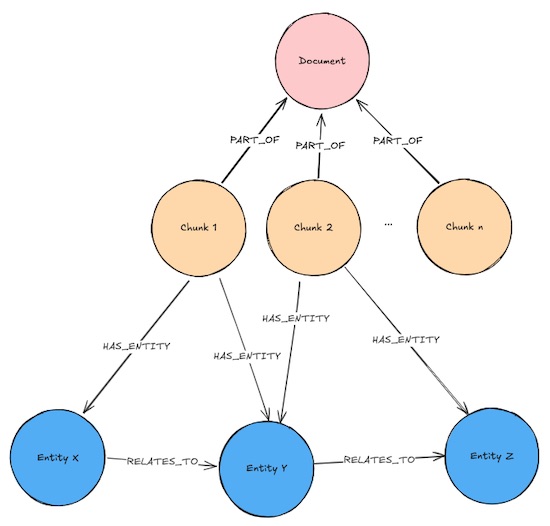
从词汇图分块中抽取出实体,从而将文档与知识图谱的结构关联起来。
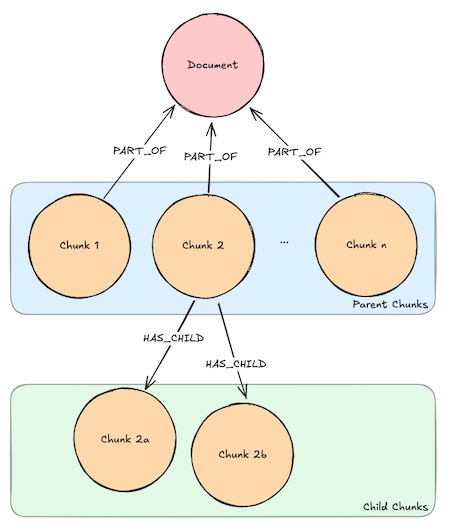
3.父子词汇图(Parent-Child Lexical Graph)
父子词汇图是词汇图的扩展,它进一步将文档分割成较大的父文本块(Parent Chunks)和较小的子文本块(Child Chunks)。子文本块用于嵌入处理和相似性搜索,而父文本块则用于在生成答案时提供更广泛的上下文信息。这种结构在父子检索器(Parent-Child Retrievers)中被广泛应用,能够更好地平衡文本块的语义信息和上下文信息,从而提高检索结果的质量和答案的准确性。
工作原理
GraphRAG的工作原理可以概括为以下几个步骤:
- 数据预处理:将原始数据(如文档、业务数据等)转换为知识图谱的结构化形式,包括实体识别、关系提取和嵌入计算等。
- 检索:根据用户的查询,利用知识图谱的检索能力,快速定位与查询相关的实体、关系和文本块。检索过程可以基于关键词匹配、语义相似性计算等多种方式。
- 上下文扩展:对于检索到的文本块,通过父子词汇图等结构,获取其上下文信息,以增强语言模型对检索结果的理解。
- 语言模型生成:将检索到的文本块及上下文信息输入到语言模型中,生成最终的答案。可以根据用户的查询意图和检索到的知识,生成总结、翻译、解释等多种形式的回答。
优势
- 高效的数据管理:知识图谱的图结构能够高效地存储和管理复杂的数据关系,支持快速的查询和检索。
- 语义理解与检索:通过嵌入技术,GraphRAG能够实现对文本数据的语义理解,从而提供更精准的检索结果。
- 灵活性与扩展性:知识图谱的灵活性使得GraphRAG能够适应不同领域和不同规模的数据,具有很强的扩展性。
- 增强的语言模型性能:知识图谱为语言模型提供了丰富的背景知识和上下文信息,显著提升了语言模型在各种语言任务中的表现。
应用案例
GraphRAG通过高效的知识管理和精准的信息检索能力,为不同行业和任务提供了创新的解决方案。以下将从行业应用、推理任务以及与深度研究的对比三个维度,详细介绍GraphRAG的应用案例,展示其在实际场景中的优势和价值。
行业应用
在医学领域,GraphRAG被用于构建高级聊天机器人,通过检索增强生成技术将结构化的生物医学知识与语言模型相结合。该系统通过识别和精炼与年龄相关性黄斑变性(AMD)相关的医学摘要中的因果关系及命名实体,开发一个全面的知识图谱2。利用基于向量的检索流程和本地部署的语言模型,该框架生成的回应既具有上下文相关性又可核实,并直接参考临床证据。实验结果显示,该方法显著减少了幻觉,提高了事实精确度,并改善了生成回应的清晰度,为高级生物医学聊天机器人应用提供了一个稳健的解决方案。
推理任务
在知识图谱的溯因推理任务中,GraphRAG通过生成逻辑假设来解决知识图谱不完整性和推理效率问题。例如,基于知识图谱的强化学习(RLF-KG)技术,利用近端策略优化(PPO)来最小化观察证据与从生成的假设中得出的结论之间的差异3。通过结合强化学习技术,该方法直接提高了生成假设的解释能力,并确保在推广到未见的观察结果时的有效性。在FB15k-237、WN18RR和DBpedia50等数据集上的实验结果表明,该方法在所有三个数据集上,通过两个评估指标衡量,优于监督生成基线和基于搜索的方法。
与Deep Research对比
在深度研究任务中,GraphRAG通过整合外部工具使用代理来增强语言模型的推理能力。例如,Agentic Reasoning框架通过集成外部工具(如网络搜索、代码执行和结构化推理上下文记忆)来解决需要深度研究和多步逻辑推理的复杂问题4。该框架引入了思维导图代理,构建了一个结构化的知识图谱来跟踪逻辑关系,从而提高演绎推理能力。在博士级别的科学推理(GPQA)和特定领域深度研究任务上的评估表明,该方法显著优于现有模型,包括领先的检索增强生成(RAG)系统和闭源LLM。
未来展望
GraphRAG作为一种新兴的技术框架,展示了知识图谱和语言模型结合的巨大潜力。它不仅能够高效地存储和管理复杂的数据关系,还能通过语义理解技术提供更精准的检索结果,并显著提升语言模型的性能。
随着技术的不断发展,GraphRAG将在更多领域得到广泛应用,为人们的工作和生活带来更大的便利。未来的研究方向可能包括:
- 多模态数据处理:将GraphRAG扩展到处理多模态数据(如图像、视频等),以进一步提升其在复杂现实挑战中的应用能力。
- 动态知识更新:开发能够实时更新和适应知识演变的GraphRAG系统,以应对快速变化的领域知识。
- 跨领域应用:探索GraphRAG在更多领域的应用,如金融、法律、教育等,以解决这些领域中的复杂问题。
当然,StrategyKG项目作为战略AI的开源知识图谱,也是GraphRAG在解决复杂问题方面的重要应用之一。