推理器:AI的突破与局限
推理器使得AI模型将转向更小、更便宜、更聪明的未来,但仅适用于结构化任务,创造性仍然是AI尚未突破的领域。
陈加兴
StrategyLogic创始人
陈加兴
StrategyLogic创始人

推理器(Reasoners)打破了主流的暴力求解方法,不需要更大的模型就能提高逻辑处理和解决问题的能力。这使得人工智能模型将转向更小、更便宜、更聪明的未来,堪称一场大卫击败歌利亚的神话。但推理器仅适用于结构化任务,创造性仍然是人工智能尚未突破的领域。
基于海量参数的大模型方法对应人类思考的系统1,提供快速而又不假思索的反应,而人类在面对复杂局面时,需要停顿、慢下来,启动负责逻辑推理的系统2。
思维链提示(Chain-of-Thought Prompting)可以让人工智能在回答之前“一步一步地思考”,从而显著提高模型输出的质量。但它只是一种对模型的调试过程,不是模型的核心能力。
推理器的出现,改变了人工智能与人的合作规则:
- 结构化思考利器
- 更小、更便宜的模型
- 在创造性方面仍有挑战
推理器:更高效的思考
推理器出现之前,人工智能的进步依赖于暴力求解:用更多的参数构建更大的模型。如果人工智能的表现不够好,答案很简单:更多的GPU、更多的数据、更多的训练。
训练大模型需要大量的算力、能源和专用硬件,使人工智能成为富有群体之间的军备竞赛。推理器引入了一条不同的路径:与其让模型变得更大,不如让它思考得更好。
推理器不会直接生成答案,而是花时间生成“思考词元”(thinking tokens)——推理的中间步骤。
它给人工智能的发展带来了巨大的影响:
- 思考的杠杆:与通过提示让ChatGPT模拟深度推理不同,推理器从解决问题的专家那里学习到了推理模式。这意味着它可以生成比普通用户更高质量的思维链。
- 思考越久越聪明:有了推理器,你只需要让它有更长的时间进行思考,它的答案就越好,而不是一直扩大模型。这意味着不再需要既昂贵又大量的数据。
推理时间计算(inference-time compute)成为新的限制。过去是花几个月的时间预训练一个庞大的模型,现在是生成答案之前花更多的时间进行思考。人工智能的能力不再受限于模型的原始大小,而是受限于我们为每个问题分配的计算量。
由于推理时间计算是动态的,人工智能不再是静态的模型智能,我们可以实时调整或调试它的推理智能。想要一个快速的答案,人工智能就返回一个快速而浅显的回应;需要深度推理,就让模型思考更长的时间。这就是人类大脑的运作方式——不必为每一个问题深思熟虑。
加速人工智能能力
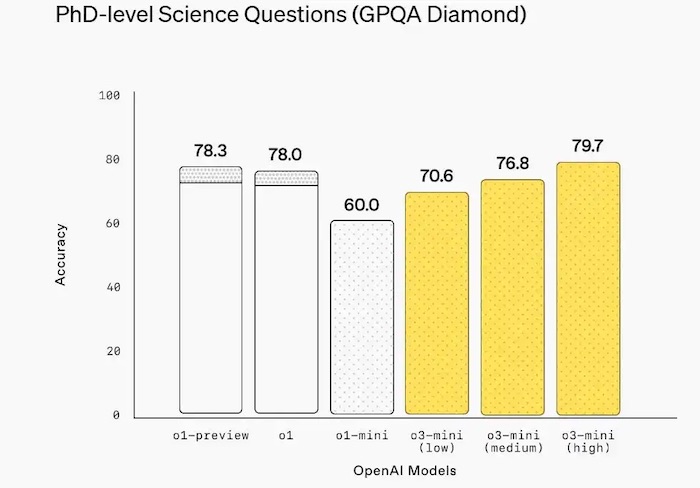
Google研究生水平的专家推理(GPQA)是人工智能的重要评估基准,由各个领域的专家精心设计,答案无法通过Google搜到,即使博士也很难通过。人类的得分:
- 专业领域外:34%
- 专业领域内:81%
很长一段时间,人工智能模型在GPQA测试中的表现都很糟糕。但有了推理器,模型在迅速改进。OpenAI o1模型综合得分达到了78%,短短几个月,又被o3模型超越。
DeepSeek R1引入了一种更经济高效的方式1来实现强大的推理能力。
1. 推理导向的强化学习
在冷启动数据上进行大规模强化学习,着重于增强模型的推理能力,特别是在推理密集型任务中,例如编码、数学、科学和逻辑推理,这些任务涉及到明确解决方案与问题的关系。在训练过程中,观察到CoT经常表现出语言混合,特别是当强化学习提示涉及多种语言时。为了缓解语言混合的问题,在强化学习训练中引入了语言一致性奖励,该奖励是根据目标语言单词在训练表中的比例来计算的。然后,在微调模型上应用强化学习训练,直到它在推理任务上达到收敛。
2. 拒绝抽样和监督微调
推理数据:通过从上述强化学习训练的检查点执行拒绝抽样来策划推理提示并生成推理轨迹。之前的阶段只包含能够使用基于规则的奖励进行评估的数据,这个阶段通过合并其他数据来扩展数据集,其中一些数据通过将基本事实和模型预测输入DeepSeek-V3进行判断来使用生成奖励模型。由于模型输出有时是混乱的,难以阅读,DeepSeek过滤掉了包含混合语言、长段落和代码块的思想链。对于每个提示,对多个回答进行抽样,并只保留正确的回答。总共收集了大约60万个与推理相关的训练样本。
非推理数据:对于非推理数据,如写作、事实问答、自我认知和翻译,采用DeepSeek-V3管道,并重用部分SFT数据集,总共收集了大约20万个与推理无关的训练样本。
3. 蒸馏:增强小模型推理能力
使用筛选的80万个样本直接对Qwen和Llama等开源模型进行了微调,这种简单的蒸馏方法显著提高了较小模型的推理能力。
因为推理者是新生事物,所以形势正在迅速变化。每个主要的人工智能实验室都在竞相构建更好的模型:
- OpenAI已经将其最新模型转变为更加专注于推理,早期版本的推理器出现在他们的01系列中,并在03中得到了显著改进。
- DeepSeek在保持推理能力的同时,开拓了降低计算成本的新方法。
- Google已经带着它的第一个推理器模型进入了这个游戏,这表明他们认识到这是未来。
这仅仅是个开始。如果你认为人工智能之前发展得很快,那么推理器将加速发展得更快。
- AI将更容易获得:使用推理器,更小的模型可以通过推理更多来实现高性能。这意味着你不需要一万亿美元的预算来构建强大的人工智能。一个训练有素、运行高效的推理器可以通过思考更长的时间来超越更大的模型。
- AI的表现将是可调整的:就像人类决定在一个问题上投入多少精力一样,未来的人工智能系统将让用户选择推理的水平。快速总结还是深入分析?选择权在你。
- 人工智能将从预测走向理解:传统的人工智能模型在预测句子中的下一个单词方面表现出色,但在理解复杂的多步骤推理方面表现不佳。推理者将人工智能从善于猜测转变为善于思考。
- 真正的AI竞赛才刚刚开始:如果推理者可以用更多的思考时间胜过大规模模型,整个行业的激励结构将会改变。我们可以看到更多样化、更专业化的人工智能系统,而不是将所有人工智能能力集中在少数几家大公司。初创公司可以在不需要数十亿美元的计算设备的情况下竞争。
更人性化的AI?
人工智能朝着这个方向发展,有些诗意。人工智能不仅仅是预测单词,它现在还在学习停顿、反思和推理——这些都让人类的智能变得如此强大。
有史以来第一次,人工智能不仅比我们快,而且开始像我们一样思考。这改变了一切。
推理器的极限——创造力
虽然推理者在答案明确的任务中表现出色,但当规则不那么严格时,他们的表现就会下降。在我自己的测试中,我发现推理者——因为他们接受了强化学习的训练——经常在创造性的任务中挣扎,比如讲故事、诗歌,甚至某些类型的编码项目。
问题在于他们如何学习。强化学习是关于优化定义明确的成功——当模型得到正确答案时奖励它,当它没有得到正确答案时惩罚它。这对于数学、逻辑和事实推理等结构化任务非常有效,因为这些任务有客观的正确性衡量标准。但创造力不是这样运作的。
创造力让推理器困惑
在写文章、作曲或编写开放式代码时(游戏邦注:比如设计一个新的游戏机制,而不是修复一个语法错误),不存在单一的“正确”解决方案——只有许多可能的好方案。而这正是推理者经常失败的地方。
比起创造富有想象力或原创的内容,他们往往会变得过于死板甚至无聊,喜欢遵循已知模式的回应,而不是冒险。这就好像,当面对一个开放式的创造性挑战时,他们会问:“最有可能的正确答案是什么?”而不是“最有趣或最新奇的答案是什么?”
在测试推理者的创造性写作任务时,我亲眼看到了这一点。像GPT-4这样的传统大型语言模型可以想出疯狂的、意想不到的情节转折或诗意的短语,而推理者通常默认是平淡无奇的、可预测的反应。即使被鼓励“更有创造力”,他们似乎也不愿偏离安全、传统的想法太远。
编码——推理器不一定更好
乍一看,编码似乎是推理器的完美用例——毕竟,代码有严格的正确和错误的答案,不是吗?不总是正确的。
对于简单的调试或结构良好的编程问题,推理器非常出色。他们一步一步地分解问题,自我验证他们的工作,并迭代找到正确的解决方案。但是,在需要架构决策、新颖的问题解决或非常规方法的项目中,推理者会遇到困难。他们不像有创造力的工程师那样思考,而是表现得像一个过于谨慎的助手——重复标准的最佳实践,而不是探索创新的解决方案。
推理器能有创造力吗?
让AI既具有结构性又具有创造性,这是一个根本性的挑战。一些研究人员认为,一种混合方法——将强化学习与创造性数据集上的自我监督学习等技术相结合——可能会帮助推理者变得更加多才多艺。
但就目前而言,如果你需要人工智能来解决数学证明、优化代码或分析数据,推理者是一个改变游戏规则的人。如果你需要一个引人注目的科幻短篇故事或原创音乐作品,你可能仍然更适合使用传统的大语言模型,因为它倾向于随机性和模式破坏,而不是严格的正确性。
在未来,也许人工智能将能够平衡结构和创造力,但现在,推理者提醒我们一个重要的事实:思考和想象是不一样的。
推理器的未来
更小、更便宜、更专业的模型,比那些体积庞大、价值数十亿美元的同类产品表现得更好。这应该让我们重新思考我们对人工智能如何进化的一切假设。
人工智能行业,就像硅谷本身一样,一直痴迷于规模。更多的数据,更大的模型,更多的计算。人们一直认为,智能来自于将数万亿个参数堆叠在一起,就像一个孩子堆叠乐高积木一样,希望在某一时刻,整个东西都能有自我意识。
像GPT-4和Claude这样的模型运行规模如此之大,以至于训练它们所需的能源消耗相当于一个小国的能源消耗。对更大、更强大的模型的争夺已经成为一场企业军备竞赛,OpenAI、b谷歌和Anthropic都在gpu上投入了数亿美元,希望达到智能的下一个门槛。
如果我们不是让模型变大,而是让它们思考得更好呢?
更好的思考的重要性
DeepSeek R1有一个特别吸引人的功能:当问题很难处理时,它可以花更多的时间来思考。它不会盲目地急于找到答案,而是会暂停、重新评估和迭代——就像人类在解决棘手的数学问题时所做的那样。
在人工智能领域,这被称为“涌现能力”,也就是说,模型做了一些我们没有明确教它做的事情,让我们感到惊讶。这是一件大事,因为它表明推理不需要我们硬编码到模型中。相反,当适当的激励措施到位时,它可能会自然出现。
潘佳一的关键观点是,你不需要一个巨大的模型来实现这一点。你所需要的只是以正确的方式应用强化学习。
通过精心设计的训练循环和定义良好的奖励函数,即使是一个30亿个参数的模型(只是现代法学硕士规模的一小部分)也能够发展出这种紧急推理能力。而且它的预算甚至不够GPT-4一个小时的计算费用。
强化学习——人工智能的秘密武器
强化学习(RL)并不新鲜。同样的方法,让DeepMind的AlphaGo在没有研究人类玩法的情况下就能主宰人类围棋选手。它没有模仿人类,而是与自己对抗,根据输赢调整策略。
潘佳一的实验以类似的方式使用了强化学习。他的模型是在“倒计时游戏”(The Countdown Game)上训练的,这是一种谜题,玩家用算术把数字组合起来,得到一个目标值。
为什么这个游戏是一个完美的测试?
- 它有明确的正确和错误的答案。人工智能在结构化的环境中茁壮成长,在这种环境中,成功是容易衡量的。
- 它迫使人们进行迭代思考。最好的解决方案在第一次尝试时并不总是显而易见的。
- 它模仿现实世界的问题解决。模型必须检查和改进它的工作,而不是脱口而出它想到的第一个答案。
结果呢?该模型学会了自我验证自己的输出——在给出答案之前检查答案是否有意义。
这是巨大的。这意味着人工智能可以被训练得更仔细地思考,而不仅仅是思考得更快。这意味着我们可能不需要上万亿美元的模型来获得更好的结果。
未来——数以百万计的微型专用模型?
如果一个30美元的实验可以创造出一个更有效推理的人工智能模型,这对未来意味着什么?
一种可能性是,我们不再崇拜规模,而是开始专注于专业化。未来可能不是一个试图做所有事情的单一模型,而是数百万个微小的人工智能模型,每个模型都经过训练,以极高的效率处理特定类型的任务。
想想看:
- 为什么要训练一个庞大的模型去做所有的事情,而不是训练一个在一件事上很完美的小模型呢?
- 如果你的人工智能助手不仅仅是一个巨大的模型,而是一个由更小的模型组成的网络,每个模型都根据你的需求量身定制,那会怎么样?
- 如果人工智能变得如此便宜,以至于每个人都可以拥有一个个人模型,在他们的手机上本地运行,适应他们独特的思维方式,那会怎么样?
这种转变将是深远的。人工智能将变得更个性化、更实惠、更节能。人工智能可以在本地硬件上运行,而不是依赖于集中式云服务(既昂贵又缓慢),根据用户的偏好和需求进行动态微调。
开源革命——每个人的人工智能
首先,这个实验成为可能的最大原因之一是什么?开源AI。
DeepSeek R1可供任何人学习,调整和构建。它的能力一经公布,像潘佳一这样的独立研究人员就开始对它进行实验。
与之形成对比的是OpenAI和b谷歌等公司,它们将自己的模型视为商业机密,严格控制访问权限,限制研究。当企业人工智能实验室竞相垄断人工智能时,开源开发者正在悄悄地取得突破,这些突破可能同样重要——如果不是更重要的话。
这一刻感觉很像个人电脑的早期。当时,IBM和DEC以大型、昂贵的大型主机占据主导地位。随后,苹果和微软的出现向人们展示了强大的计算技术可以是个性化的、去中心化的、人人都可以使用的。
人工智能正在接近一个类似的拐点。企业人工智能实验室的闭源、大规模方法可能不是唯一的前进道路。由独立研究人员和小型团队推动的开源人工智能正在证明,小型、廉价和创造性仍然可以取得胜利。
那么接下来会发生什么呢?
潘佳一的实验仅仅是个开始。我们可能会看到:
- 在小型模型效率方面取得更多突破。当我们将强化学习技术应用于其他任务时会发生什么?我们能让小模型更智能吗?
- AI可访问性的激增。如果一个30美元的人工智能可以这样推理,那么当我们进一步推动它时会发生什么?人工智能可能很快就会掌握在每个开发人员、研究人员和修补匠手中。
- “越大越好”心态的衰落。如果更小、更便宜的机型能够更好地思考,那么整个行业将不得不重新考虑对规模的依赖。
这可能是一个新的人工智能时代的开始——在这个时代,大脑打败了肌肉,智能不仅仅是关于大小,而是关于模型的思考能力。
如果这是真的,人工智能的未来可能比我们想象的要小得多,也要聪明得多。
注释参考
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning ↩